gcc编译器在开启O2或者O3优化后,将会开启-fschedule-insns优化选项:
|
|
这个优化选项通过指令重排来减少所需数据未准备好,导致CPU需要停顿下来等待数据就绪的延迟。
除此之外,还有一些优化选项也会导致指令重排,比如重排指令以提高代码的局部性,提高cache命中率。绝大多的编译乱序指令重排并不会带来程序的执行逻辑异常,因为编译器在重排指令前会对上下文进行分析,确保重排前的指令和重排后的指令执行结果是等效的。
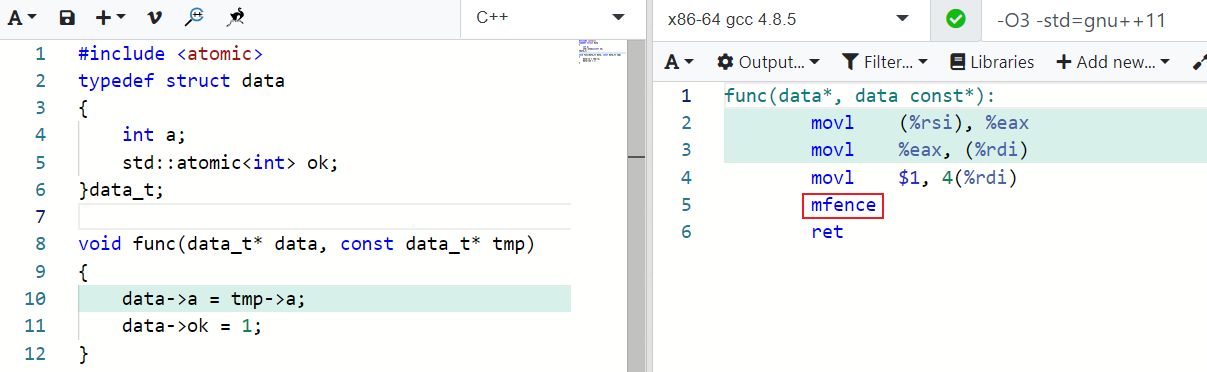
但是编译器仅能保证单线程下执行结果的正确性,多线程的执行环境下就有可能由于指令重排导致偶现的bug,而且不同编译器最终生成的指令可能会不一致,进而导致需要特定版本&特定编译器才能复现。
以下测试基于x86-64 gcc-4.4.7(Centos 6)和x86-64 gcc-4.8.5(Centos 7)
编译乱序实例
O1优化
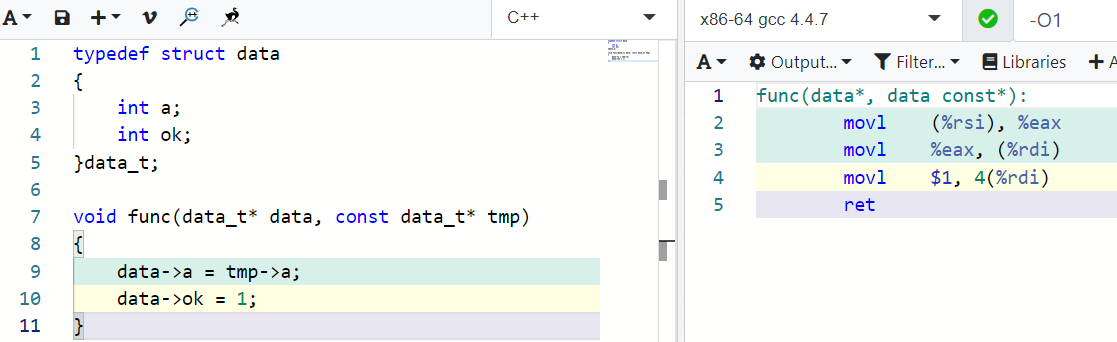
O1优化下不会开启-fschedule-insns,可以看到第9行源码最终生成了右边2、3两条汇编指令,第10行源码生成了右边第5条汇编指令,并且汇编指令顺序与源码顺序一致:
|
|
加上 -fschedule-insns
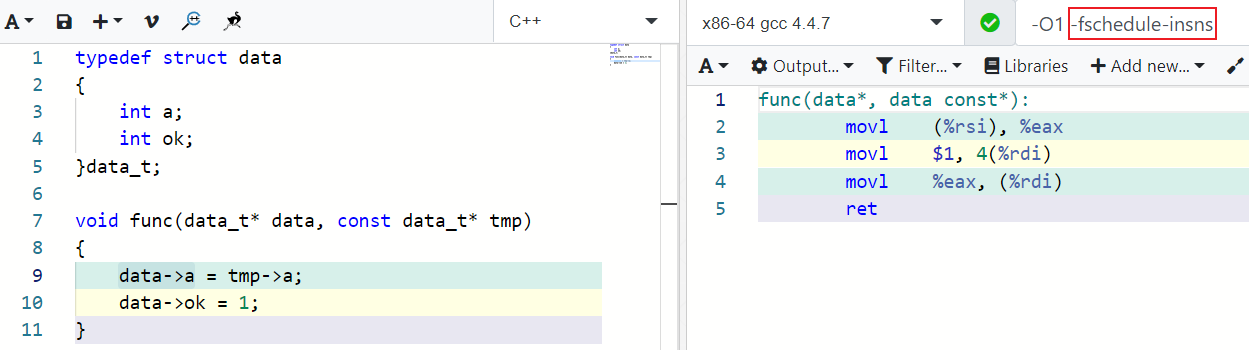
O1优化,额外开启-fschedule-insns选项后,可以看到指令被重排,3、4两条汇编指令的执行顺序交换了,立即数赋值操作被提前了:
|
|
这就导致data结构体中a和ok的赋值时序发生了颠倒,源码中期望的顺序是a先被赋值,然后ok被置为1。单线程下没有任何问题,但是假如有另外一个线程在检测ok的状态,检测到ok为1后就去使用a,那么就可能出现此时a实际上还没有被赋值的情况,比如线程执行完第3行指令后恰好被操作系统调度出去了。
优化原理
如今的计算机架构下,内存读写速度虽然很快,但相比CPU还是太慢,因此CPU内部还集成了多级缓存,其中有每个核心各自独享的缓存和整个CPU共享的三级缓存。由于内存很慢,因此CPU执行指令的过程中并不会去直接读写内存,而是通过CPU缓存去读写数据,然后再由MMU(内存管理单元)去进行脏数据回写物理内存和缓存miss时的数据装载。核心独享的缓存一致性则由MESI协议去保证。
因此执行movl (%rsi), %eax指令时,(%rsi)对应的数据可能还没有加载到CPU缓存中,因此%eax寄存器上的数据无法立即就绪,如果接下来就去执行movl %eax, (%rdi),最坏的情况需要从内存一级一级更新到L1缓存,等待多个时钟周期后%eax上的数据才能就绪,这就导致了CPU执行的停顿。
因此可以把一些指令提到movl %eax, (%rdi)之前,比如movl $1, 4(%rdi)将一个立即数写入缓存,就能最大程度的利用等待数据加载到L1缓存这段时间。
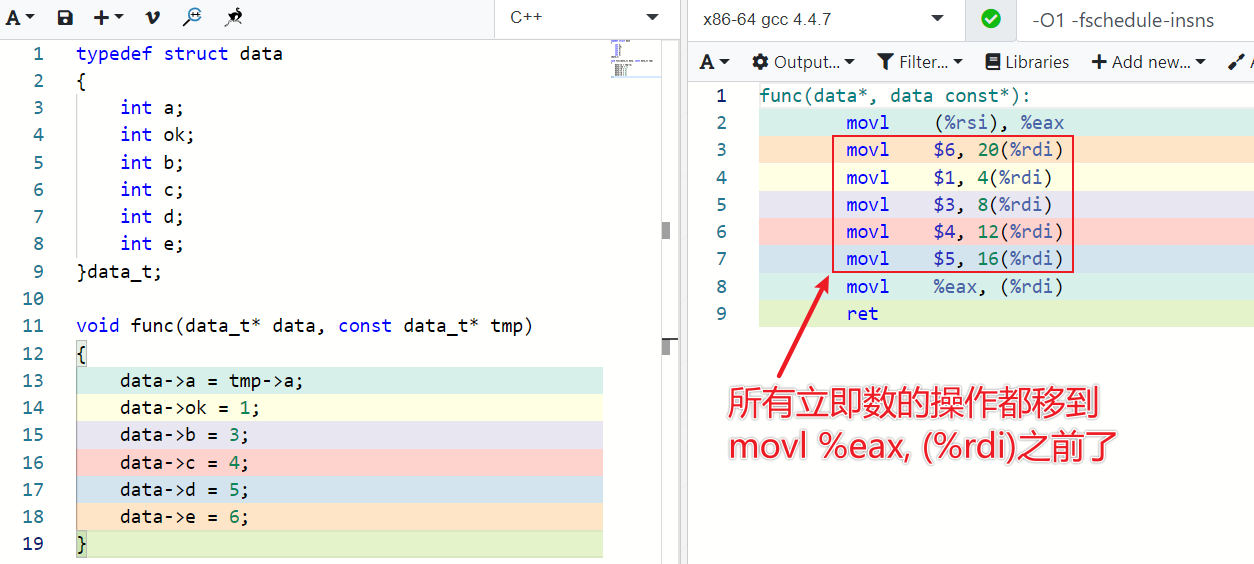
指令重排行为差异
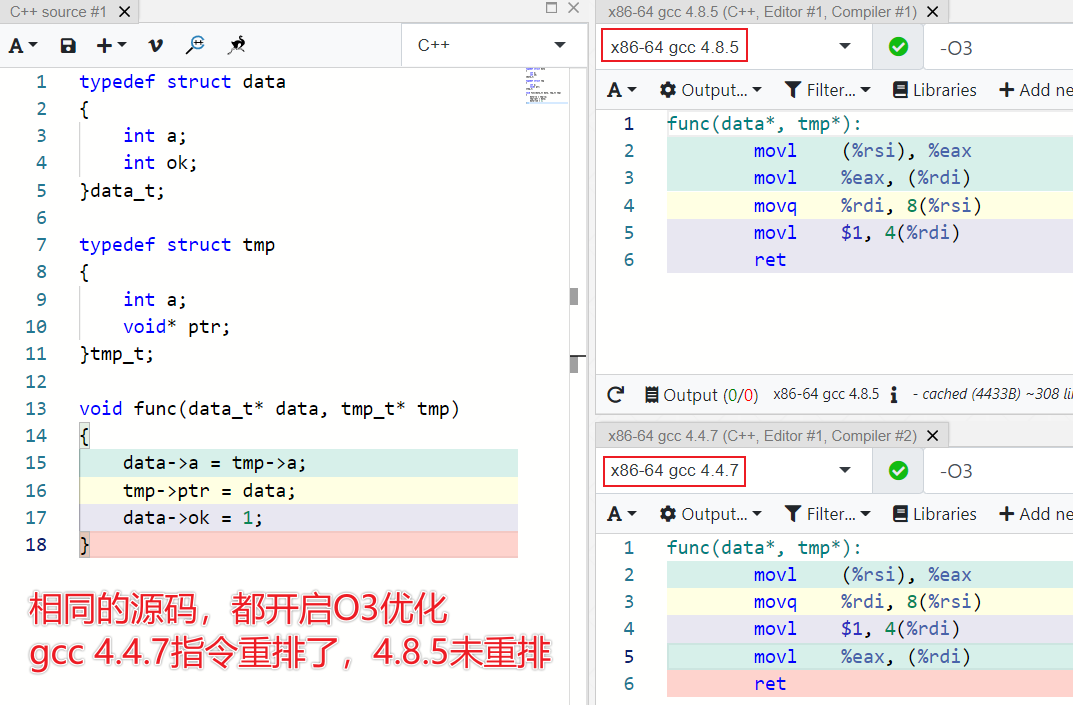
这就有可能导致gcc 4.4.7编译出来的程序存在隐含bug,而4.8.5版本下编译出来的程序没有任何问题。
防止指令重排
编译栅栏
多线程无锁编程下主要使用编译栅栏防止编译器对指令进行重排,使用方法很简单,只需要一行汇编指令:
|
|
将以上代码插入两行代码之间,将代码分为上下两个部分,就能保证上半部分代码生成的指令肯定会在下半部分代码生成的指令之前执行:
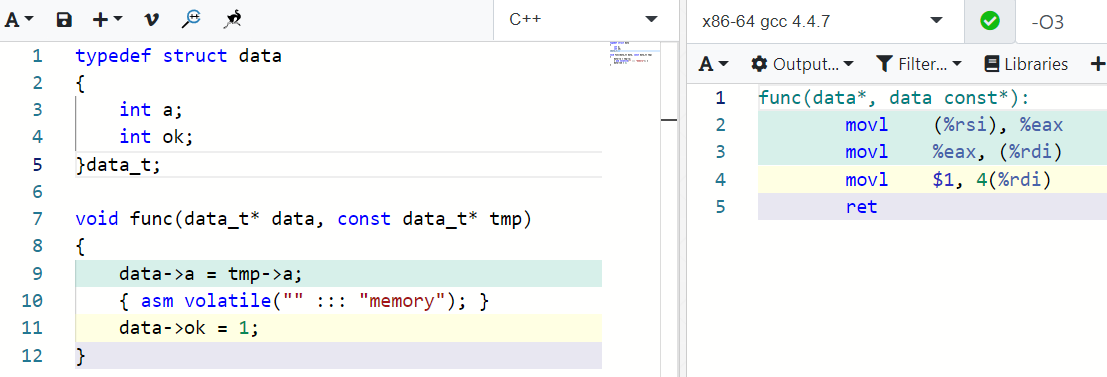
godbolt link
对比指令重排代码,加上编译栅栏后最终生成的汇编指令没有任何增减,只是执行顺序与源码保持一致了。需要注意的是上半部分指令和下半部分指令各自内部依旧可能会发生指令重排。
函数调用
没有发生内联的函数调用和编译栅栏是等效的,另外还有锁,原子变量如std::atomic内存屏障已经隐含了编译栅栏: